The 72-Hour Bug
During CS 452 lecture my professor occasionally gives examples of “72-hours bugs” — programming issues encountered by past students that required days of debugging to fix. Many of these time consuming bugs were caused by subtle mistakes such as memory alignment, off by one errors or typos in preprocessor directives. The ones I find the most interesting, however, are larger design decisions that resulted in unpredictable kernel behavior. According to the professor, the latter kind of bug has occurred several times due to improper use of static and global variables.
Global variables aren’t inherently evil. Although they can be a sign of a poorly designed system, there are legitimate use cases for globally accessible data. The problem is that when used incorrectly, globals can create non-deterministic bugs that are hard to fix. This is especially true in systems with nonlinear code, such as the CS 452 project. Our kernel uses a time slicing scheduler, so at any given time a user task can be interrupted by the system to allow another task to execute. Without adding locking primitives or using atomic operations, tasks can’t access shared memory in a safe manner:
int sharedInteger = 0;
void TaskA(void)
{
if (sharedInteger == 0)
{
sharedInteger = some_value * someFunction() + sharedInteger;
}
}
void TaskB(void)
{
if (sharedInteger == 0)
{
sharedInteger = someOtherFunction() - sharedInteger;
}
}
If TaskA is interrupted while operating on sharedInteger, TaskB might run and modify the variable without TaskA being aware. ‘sharedInteger’ will almost certainly be in a bad state after TaskA resumes and finishes execution. The same issue occurs when creating multiple instances of a task that uses a static variable — the static keyword will result in a single, shared instance of that variable being created for all of the tasks.
Globals and user space don’t mix well, but having shared data in the kernel itself is relatively safe. The CS 452 kernel isn’t reentrant; nested interrupts aren’t allowed, so during normal execution the kernel runs in a linear fashion. When my partner and I designed our system, we decided that it was acceptable to store kernel data in a global struct. This made it easy for syscall handlers, the scheduler, etc to access the necessary system components in a way that was convenient for us, the programmers. I was hesitant to do so at first, however it ended up working well for the first three kernel milestone we submitted during the course.
A Not Quite 72-Hour Bug
Over the last day or so my partner and I struggled with a critical bug in our kernel that was particularly difficult to isolate. We checked for many of the obvious problems like stack overflows and uninitialized data; we turned off caching, disabled interrupts and inspected the GCC assembly output. It wasn’t even clear if the problem was a single bug or a collection of multiple errors that had surfaced all at once. Spoiler: the problem was indeed related to global data, but not in an obvious way. The symptoms were, in increasing order of peculiarity:
- The code ran normally when compiler optimizations were off. Problems always appeared with optimizations on.
- Adding print statements to various places in the kernel caused the system to execute normally, but hang on exit.
- Using delay loops instead of print statements, or any other code for that matter, did not have the same effect.
- The code could be made to run by only turning on optimizations for a subset of the code. After the partially optimized code terminated and returned to the bootloader, attempting to load and run any other program would cause the hardware to hang. Other bootloader functionality worked fine.
- The bug seemed to be partially related to the size of code. Removing some of the test processes made the system work, even if the test processes weren’t actually being executed.
- In certain circumstances, attempting to read from a memory mapped IO device would fail
Our professor heard about our situation from the TA and stopped by the lab to offer some advice. He wasn’t able to identify the problem, but one of his suggestions helped point our debugging efforts in the right direction. Fortunately it “only” took a total of 12 hours of work to resolve and understand the cause of the bug. In hindsight, the last two bullet points should have been a strong indicator that something was wrong with the memory layout and/or global variables. I was caught up in understanding why the optimization settings and print statements changed the system behavior, and deduced that we’d somehow put the interrupt controller into a bad state.
Memory and Code Layout
Understanding the nature of the bug requires some background information on the memory layout of the hardware. The board we use has a total of 32 megabytes of memory. The first 280kb or so are used by the system for various configuration and initialization purposes. Addresses 0x00 to 0x40, for example, are the interrupt vector table. On the opposite end of the memory is the bootloader stack and the location that the kernel stack pointer starts at. The exact address depends on how much memory the bootloader has used, but it’s usually no lower than 0x01fd0000. In other words, the region of memory considered “safe” to use is between addresses 0x00044000 to 0x01fd0000:

memory layout of the hardware (not to scale)
The compiled code itself is also composed of several distinct sections. The .text block comes first — this contains all of the executable code. A special subsection section at the beginning named .init has the initialization instructions, and the .vector subsection holds the IVT. After .text there are several other sections that aren’t relevant to this post. Among other things, these contain read-only data for constants like strings or defines. At the very end is a block known as the BSS segment, which is a region of memory that holds the program’s uninitialized global variables, such as the kernel data structure.

code sections (not to scale)
Two components are responsible for determining which memory address to load the code into. The first is the linker script, which defines the section order and base address for the executable. The second is the bootloader itself, which can load the code at any address within the safe memory area.
At compile time the assembler and linker don’t know where in memory the code will be placed when it’s running on the hardware. To get around this, relative addressing is used any time a branch or stack memory access is needed. Rather than jumping to the absolute address of a function, for example, the code will branch to a location using an offset from the current program counter. Relative addressing is also used to access read only data and constants, since the linker knows where those sections are in relation to the code itself.
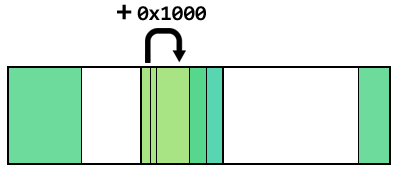
a relative branch from one portion of the code to another, with an offset of 4096
Misplaced BSS Segment
Rollen and I wanted our system to be completely position independent, so we set up our linker script to use a base address of 0. The desired load address was passed in via the bootloader; relative addressing meant that code would run fine at whatever address was used. There are a few cases, however, where absolute addresses are still necessary. In CS 452, configuring the interrupt vector table and setting up task entry points are the two main examples. We handled these cases by storing off the program counter in the initialization code and using it as a “base address” when installing our IVT and creating user tasks.
Everything worked fine except for one important detail: the BSS segment was not accessed using relative addressing. When GCC produced assembly instructions that made use of global kernel data it assumed that it could access the data using an absolute address. The address was computed from the base address in the linker script and the position of the BSS relative to rest of the code. Since the base address was set to zero, the code assumed the global variables were located at addresses in the range 0x2000 to 0x3000. This effectively meant that our global kernel data was stored inside one of the unsafe memory regions.
The bug existed in our code since we first started working on the kernel, however because the code size was small it never ended up causing any harm. Had we checked the memory address of the kernel struct it would have been immediately apparent that something was wrong, but since the code was working neither of us thought to do so. At some point we added enough code to push the data structure into a place where using it corrupted the system itself. This explains why our code as able to break the bootloader and memory mapped IO devices. It also explains why disabling optimizations was able to “fix” the bug — GCC’s optimization process can change code size and reorder instructions.
The fix we ended up using was to change the linker script to use a base address within the safe memory region. We also stopped using the bootloader to specify the load address and always place the compiled code at the base address specified in the ELF binary. This simplifies things somewhat, at the expense of no longer having a position independent kernel.
Going Forward
After the bug was fixed, I spent the remainder of the day adding asserts and error checking to our kernel in hopes of preventing future issues. We now have a much more robust set of validation macros that can be enabled or disabled using compiler flags. I also added a proper assert function that dumps useful information to the screen and then resets board:
the kernel panic screen for our operating system; ASCII art included for comic relief
At some point down the road, I think I’ll write a post on the techniques we used to debug our kernel. Since the IO wasn’t working consistently, some of our debugging was done by writing to memory locations and inspect the values using the bootloader. Using blocking IO can also introduce or mask timing errors, so unless the hardware vendor provides some sort of debugging module there aren’t many other options. Those experiences are a story for another day.